聊聊知乎盐选反爬 (回答页篇)
最近,知乎上线了针对专栏[1]中盐选文章的反爬系统,随后该系统也被运用在知乎回答页面中的盐选文章上。具体表现为爬取的文章内容中出现大量的错乱词汇。而在本篇文章中,我们将一步步带领各位解开这些乱码。在这个过程中,我们将对字体反爬有更深入的认识,并学到运用字体反爬时需要注意的问题。
一、知乎反爬效果
来自知乎回答不被爱是一种什么样的感受? - 知乎
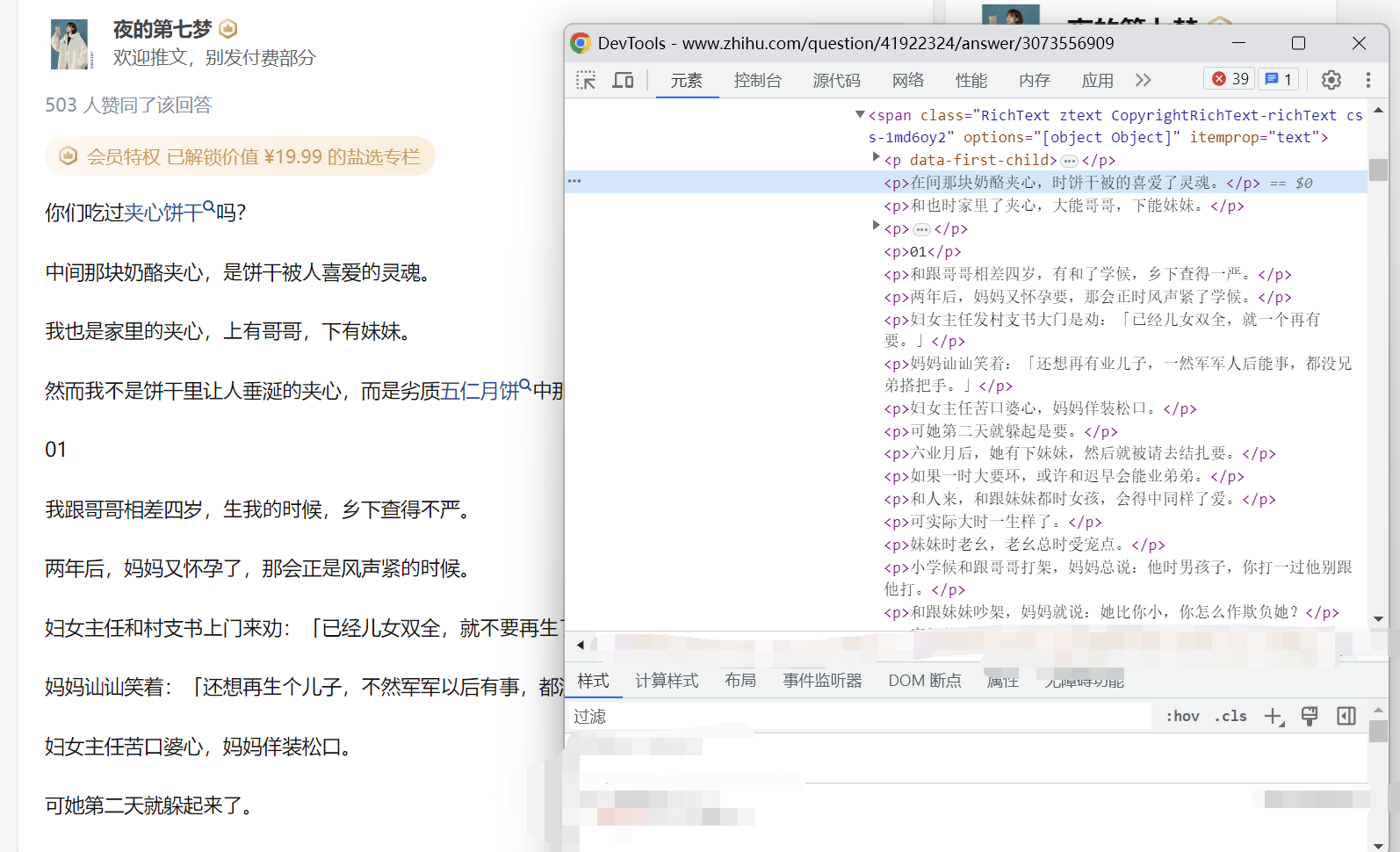
如图所示,在页面源码中出现了大量乱码,例如(原字,错字):[2]
- 中 -> 在
- 是 -> 时
- 上 -> 大
这些乱码使得文章可读性大大下降,那么乱码是怎么产生的?又如何解决这个问题呢?
二、找寻乱码真凶
观察上述现象,页面源码中的字,在被显示到页面后,居然变成了正确的字。因此我们初步推断知乎在该页面运用了字体反爬。
接下来我们打开 F12 -> Network 页面,选择 Font,观察知乎加载的字体。
右键选择 Open in new tab 将字体保存下来。
将字体后缀名改为 .ttf [3] 并打开。
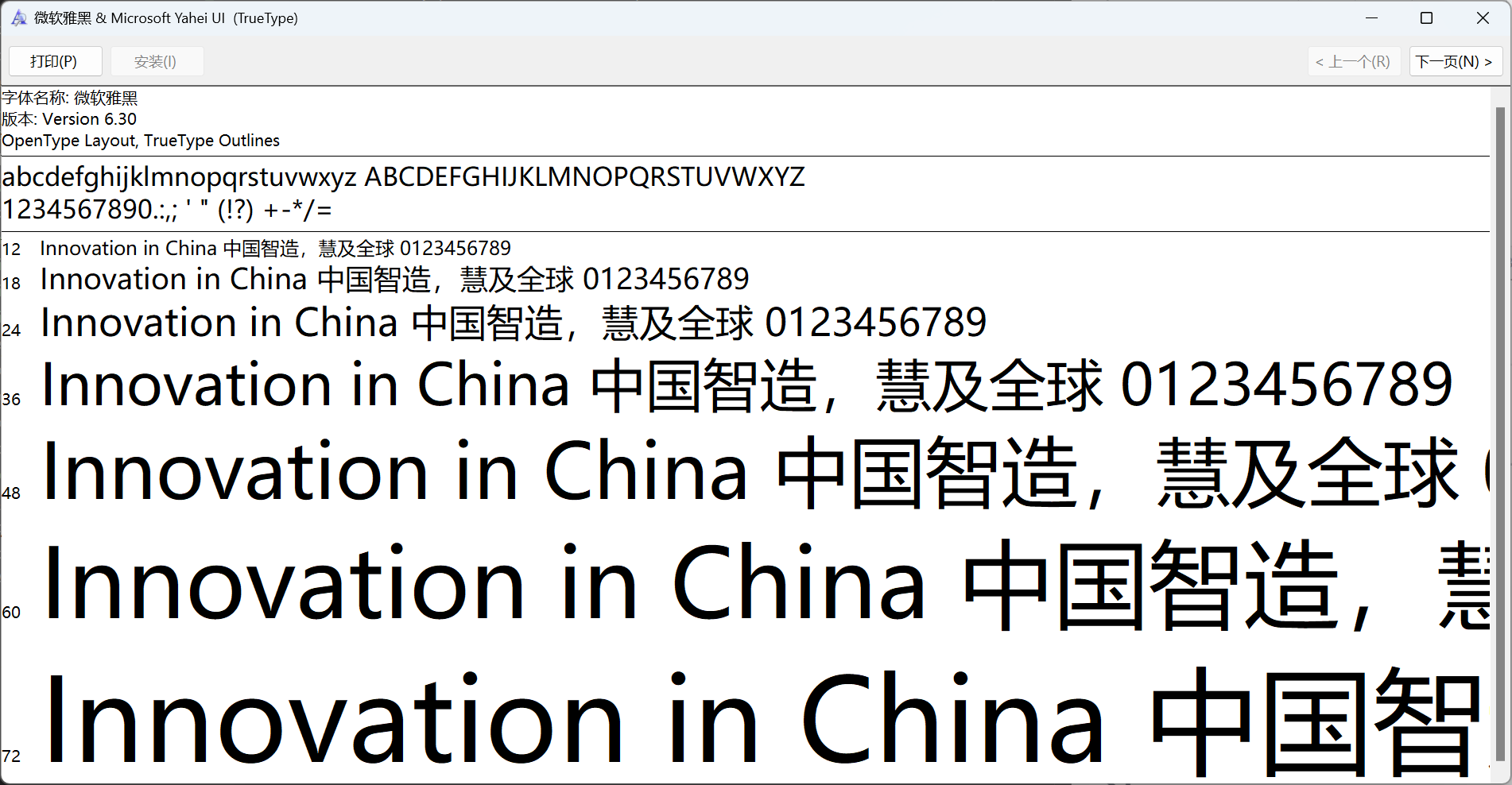
与正常字体对比,我们下载的字体明显替换了部分字体,这便是知乎用于反爬的字体了。接下来我们将分析这个字体并给出应对方案。
三、致命缺陷
字体反爬的根本原理是替换原本的字为一个新字,再用字体将新字渲染为原字,这样对程序而言就只见到新字而不是旧字了,而用户看到的还是原本的内容。因此只要找到新字与原字间的对应关系便可解决该反爬。而要找到这个对应关系,抓住字体中各个字形的特征是必不可少的一环。
我们打开 FontDrop! 加载字体,向下翻,观察字形的特征。
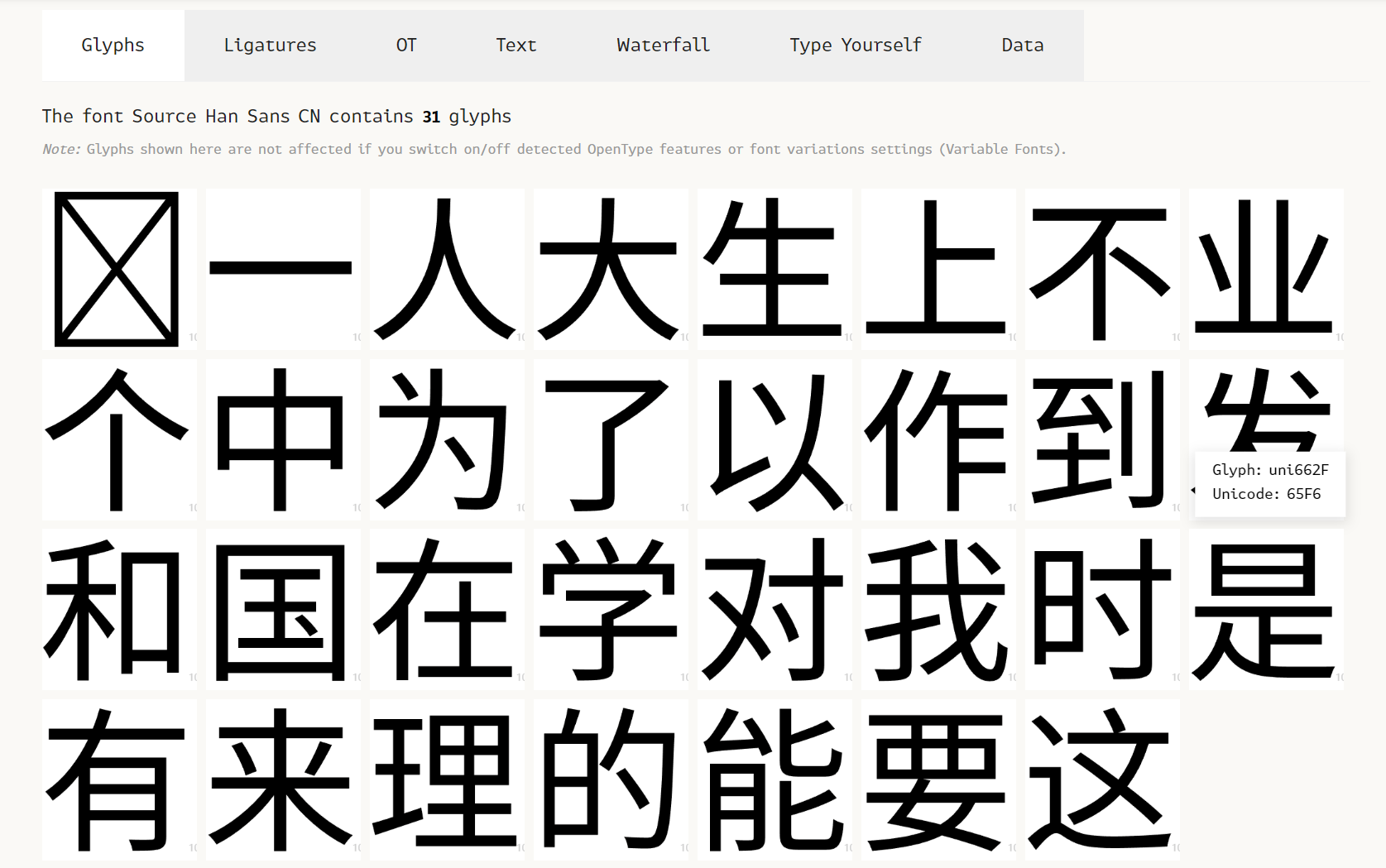
我们发现字形的 Glyph 为 uni662F 而 Unicode 为 65F6,接下来我们试着查询这两个十六进制数对应的字:
1 | |
正好,上文提到,「是」在源码中被替换为了「时」。知乎在反爬字体中保留了原字与新字的对应关系,为我们提供了一个极为便捷的捷径。我们可以直接读取这个对应关系,而不是比对每个字的笔画[4]。然而,这也是其字体反爬系统的致命缺陷,各位在自己的网站运用字体反爬时也要注意这一点。
至此,字形的特征与对应关系都被我们分析出了,接下来我们将编写程序从字体中提取对应关系。
四、提取对应关系
要提取各个字间的对应关系,首先我们需要安装 fontTools [5]。
1 | |
用 ttLib.TTFont(filename) 打开字体:
1 | |
初始化一个存储对应关系的字典:
1 | |
遍历字形,获得其 Glyph 与 Unicode,并写入字典(注意这里的Glyph对应的字可能不是标准的字,比如是康熙部首[6],因此我们要对其标准化[7]):
1 | |
(这里的 cmap 是一个 dict,是字形的 {Unicode: Glyph}[8])
接下来,我们将使用得到的对应关系将带乱码的文章转为正常文章。
五、去除乱码
这段代码很简单,不作解释。
1 | |
六、全部代码
1 | |
温馨提示:上面字体文件名记得换成你自己下载的字体文件名
结语
在本文的带领下,我们粗略地了解了知乎所使用的反爬技术,分析了其使用的反爬字体,找出了原字与新字的对应关系,最终将带乱码的文章转为了正常文章。其中,知乎使用的反爬字体没有去掉 Unicode 与 Glyph 的对应关系,虽然这使我们更轻松地得到了对应关系,但是对于知乎而言,这种错误无疑是致命的,因此,在字体反爬的实际运用中,我们更需要避免这种错误。[9]
知乎也在该反爬系统部署到回答页不久以后升级了其专栏反爬系统,本文所介绍的致命缺陷已被修复[10],而解码新反爬系统的内容,就留到本系列的下篇吧。
(敬请期待)
友情链接
- C的云存储 - C的云存储所有作品均由用户提供上传分享,仅供网友学习交流!若您的权利被侵害,请联系 357158361@qq.com
- GitHub - cxzlw/zhihuDecrypt
- GitHub - cxzlw/zhihuDecryptApp: The app to decrypt zhihu’s encrypted (probably not) passages.
- 专栏反爬现已更新,故本文只以回答反爬为演示。 ↩
- 由于知乎回答页反爬使用了两套字体,故本文所有截图,代码运行结果等内容可能与实际不符。你可以选择以实际为主或刷新页面直到页面显示的内容与本文一致。 ↩
- .ttf 是因为
data:font/ttf;...代表该字体是 ttf 格式的。 ↩ - 基于笔画比对的反爬破解见该文章:字体反爬之汽车之家51CTO博客汽车之家字体反爬(话说这篇文章和下面注 9 是一个网站吧) ↩
- fontTools文档:fontTools Docs — fontTools Documentation ↩
- 康熙部首相关文章:康熙部首导致的字典查询异常 ↩
- 标准化相关文章:化异为同,Python 在背后帮你做的转换 ↩
- 其中 Unicode 为
int而 Glyph 为形如 uni4E0D 的str↩ - 关于如何创造更坚固的字体反爬系统,可以参考这篇文章:反爬终极方案总结—字体反爬 - 知乎(值得一提的是这篇文章就被发表在在知乎上 2333) ↩
- 值得表扬 ( •̀ ω •́ )y ↩